
A Version Control System (VCS) is a software commonly used to track changes to a project and allow easy collaboration. Git is one of the most common version control systems out there. Git can be used to track changes to individual files in a project, roll-back accidental changes, and, guess what? bring back accidentally deleted project files in some cases.
Git can also help you merge the changes made by different collaborators on the same file and much more. Isn't that cool? By default, Git tracks changes across all files where it is initialized. When Git is installed on your computer, you can easily start tracking any folder using simple commands. A folder that is being tracked using Git is called a git repository or git repo, in short.
git init git add .git commit "minor changes"These are a few simple git commands to give you an idea of how easy it is to use Git. You can find many examples online, so you can simply start using Git and learn the commands along the way.
The .gitignore file
Ignoring the files means telling Git not to track changes to them. That also means you cannot roll back accidental changes made to that file. The file is mostly used to avoid committing transient (short-lived) files from your working directory that aren’t useful to other collaborators, such as compile-time logs, build folders and outputs, temporary files IDEs create, etc.
To tell Git not to track some files, we put a file called .gitignore in the folder that is being tracked by Git. The .gitignore file tells Git which files or folders it should ignore. A file named .gitignore usually resides in the project’s root folder. Here is a simple project that is being tracked by Git. Notice the first folder named .git? Git creates that folder for keeping track of the changes in the files in this project. Also, notice the file at the last? That's the .gitignore file right there!

How to create a .gitignore file
Some tools & IDEs will generate a .gitignore file automatically when you start a new project. If you have cloned a project from an existing remote repository, it probably has a .gitignore file already. If you don’t see a file named .gitignore, you can create a new .gitignore file yourself. Either you can use a text editor, or any command or trick you know to create a new file and name it .gitignore. It's that simple. From the terminal, you can do touch .gitignore or from your File Manager, right click and select the Create New File or similar command. Or you can create a new document in a text editor and save the empty file while giving it the name .gitignore.
Example of a .gitignore file
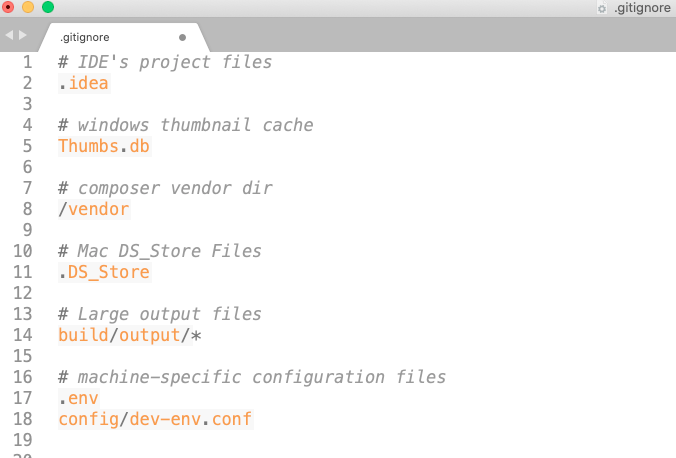
GitHub maintains a repository of .gitignore files for almost all languages and frameworks. You can look for the one that you need from the following URL https://github.com/github/gitignore. Download the appropriate file and copy it to your project’s root folder, then rename it to .gitignore by removing the filename. Even if you already have a .gitignore file in your project’s root folder you can look at the contents of the file there, and make necessary changes in your own .gitignore file. This is what a gitignore file looks like. The lines starting with a # are comments that are optional. I prefer keeping a comment so I know why I ignored that particular file at that time.
When to create a .gitignore file
Ideally, you should create a .gitgnore file as soon as you start your project, even if it is empty. It's best to initiate a git repository after creating the .gitignore file. That helps git identify the files that do not need to be tracked. If you add a .gitignore file in the git repository where the files are already tracked, you need to manually remove and un-track the already tracked files. That's why it is a good idea to make the .gitignore file one of the first ones in the git repository. If you need to ignore a file that is already being tracked, you need to do that individually using the following command:
$ git rm --cached PATH_TO_FILEPersonally, I prefer to add a .gitignore file and a README.md file as soon as I create a new project.
Why create a .gitignore file
This is one of the most common questions that a beginner asks. Why should you ignore some files in the repository instead of checking them all into Git? That's because not all files in your working directory are useful or relevant to you or other collaborators. Some files can even contain information that you'd like to store temporarily. When you check-in a file to git, all the changes to it are stored in git, which might not be necessary. If you are not sure whether you should keep a file/folder or ignore it, the following examples will give you an idea.
1. Ignore Large Files
We usually don’t add large files to the VCS to limit the size of our repositories. To do that, as soon as the new files or folders are added, we add them to the .gitignore file. Even if you accidentally added and then later deleted the file, the size of the repository will always be way larger than it should have been. When you check in large, unnecessary files, it takes much more bandwidth and storage than is necessary. Unless the files are extremely important for the project to run and cannot be shared by other mediums like local lan-share or uploaded to a common cloud drive, such files should be ignored.
2. Ignore libraries, archives, build outputs, etc.
Sometimes you might have downloaded a collection of assets, or an entire library or datasets to work on the project. Instead of tracking the file on the VCS, add a message on the README file about how and where to find those extra files. Most modern build tools let you define the requirements in files like package.json, composer.json or requirements.txt, etc. Such libraries are stored in separate folders like node_modules or vendors or packages. In this case, the libraries can be re-downloaded from the Internet whenever someone else clones the repository. Adding the third-party libraries into your git repository, and tracking changes to all of them is unnecessary.
3. Ignore temporary files
It’s a good practice to have a folder named tmp on your project root, and ignore it by adding a new line, tmp/, in the .gitignore file. You might as well add large and non-essential files to this directory because they will not be checked into the VCS. Other examples of temporary files include temporary databases, or temporary folders mounted as docker volumes during local development. Personally, I create a folder named "tmp" in all of my projects and ask git to ignore it. Then I don't have to worry about accidentally adding unnecessary files because everything temporary goes inside that folder.
3. Local and Environment-specific files
Your development environment might not match your staging or production environment. The settings of your IDE, your local database credentials, paths to your local libraries, and your SDK path might not match that of your coworkers. In that case, whenever your changes are pulled by other members of the project, the project might not build because of mismatched configuration & missing files. That’s why people keep such configuration in a single file and ignore it using the .gitignore file. One example of such files is local.properties in an Android app project that includes the local Android SDK installation path, which looks like "sdk.dir=/Users/nj/Library/Android/sdk" on my computer. If I forgot to ignore the file and someone else clones the repository, the IDE cannot find the build tools in that folder. They need to change the file location to something else. When they push their changes back, I need to change the file again to make it work. This doesn't look like a great idea, does it? If we ignore the file altogether, both of us can have a local copy of the local.properties file in our working directory and not worry about overriding each other's settings.
Another common example is a file named .env which contains the environment variables for the project. Environment Variables – The name tells us that the variables will differ in different environments. Since that particular file may also contain confidential information, I'm breaking it down into separate bullet points below.
4. Credentials, Secrets and Environment Variables
If your project depends on third-party services you might need your secrets and credentials in order to make use of such services. Also, you need different types of settings when you're running a project in a production server, staging server or your local development machine. You definitely don’t want your production database password to be available to everyone in the organization or the public. That's why all confidential information is usually stored in a file, which is not shared between the environments. An example of such a file is the .env file in a web-based project that includes your credentials of a database server, API keys, and other secrets. Each environment (local, development, staging and production) has a different copy of the file.
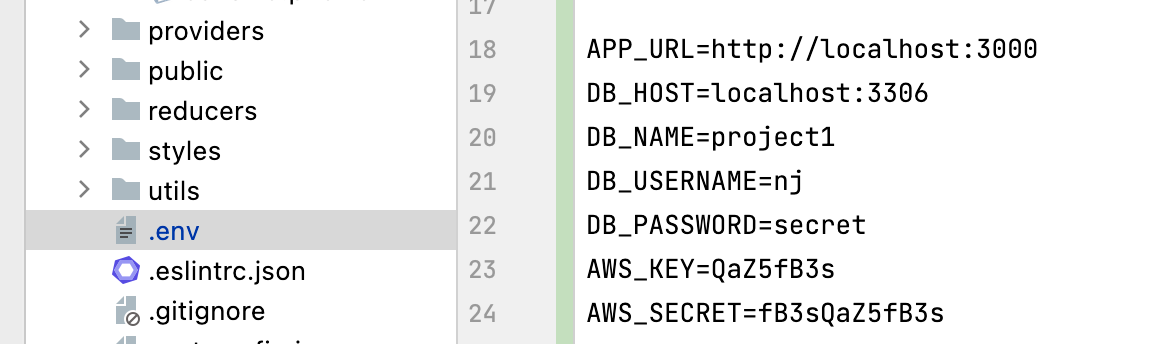
The above file looks completely different in the production server, where the password might be longer, the database host might not be localhost, and the AWS key and secret would definitely be longer.
You should NEVER add the files containing secrets or confidential information like passwords and secret keys to git. That's because the credentials and API keys and secret should be transmitted over a secured channel like SSH or using vault. Most developers add a file called env.example alongside the .env file and only add the keys, omitting the values make it easy for the collaborators.
Things to remember about the .gitignore file
- The .gitignore file itself should be checked into the VCS along with the other files, which means you should not add the line /.gitignore in the .gitignore file.
- If you had accidentally ignored the .gitignore file itself, delete that line, then run the command
git add .gitignoreto start tracking the file again. - Closely monitor the changes to the .gitignore file to ensure no files that need to be tracked are accidentally added to it.
- As the .gitignore file is a hidden file, it sometimes gets lost when you copy-paste the project contents to a different folder. Sometimes the entire .git folder is lost too, so take special care while copying contents from a local repository.
Common Problems
While telling Git to not track a file seems trivial, most beginners run into at least a problem while creating and using a .gitignore file. Here are some of the common problems that I have found.
1. The .gitignore file is not visible (hidden by filesystem)
The .gitignore file might not be visible on your file manager (My Files, My Computer, Finder, Folder, whatever it is called) because it is a file with only an extension; it doesn’t actually have a filename. Since the filename itself starts with a dot (full stop, or period), your operating system considers it a "hidden" file. You need to enable showing hidden and system files appropriately to be able to see the file.
Terminal window
To show the hidden .gitignore file in the current folder, type ls -a and hit enter.
Linux Desktop
Open the "Files" or "F application, navigate to the folder and type Ctrl + H (hold the Ctrl key and press H once) to show hidden files.
Mac OS
Open the "Finder" application, navigate to the folder and type command + shift + . (hold the Command key, hold the Shift key, and press the full-stop or period key) to show hidden files.
Windows PC
On Windows, follow these steps to show the hidden .gitignore file:
- Open the File Explorer app
- From the View menu, select the Folder & Search Options option
- Switch to the Folder Options tab
- Check the Show Hidden Files option
- Uncheck the Hide Operating System Files option (optional)
- Close the Folder & Search Options window
- All the hidden files will be visible
Thanks for reading. Subscribe using either of the buttons below for more!