

Introduction
The vast majority of internet users have streamed media online, from music on Spotify to videos on YouTube. Delivering media efficiently to millions of concurrent users presents a significant challenge. As user bases grow, so too does the strain on server load, encompassing both processing power and bandwidth.
Traditionally, HTTP servers transmitted entire media files to requesting clients at once. Even if a viewer only intended to watch a small portion of a video, the entire file would be sent. This approach wasted bandwidth for both the client and the server. This is also beneficial to consumers on mobiles as it uses less data.
Modern advancements in HTTP protocols and HTML5 have enabled us to embrace chunk-based media streaming. This method allows clients to request media in smaller segments, eliminating the need to transmit the entire file upfront. This approach is now ubiquitous across streaming platforms; for instance, YouTube employs chunk-based streaming to deliver videos.
In this blog post, we'll discuss the inner workings of chunk-based streaming. We'll explore a sample media server built with Typescript and Bun, employing ElysiaJS as the web framework and SQLite with Prisma ORM for database management.
Understanding Chunk-Based Streaming
Once you've cloned the provided repository and set up the server, initiate the development server using the command bun dev. The API server should be running on port 3000, while the web server runs on port 3001. All the endpoints are defined in the file apps/api/src/index.ts. To access the Swagger UI, navigate to http://localhost:3000/api/swagger. Here, you'll find three endpoints:
POST /api/uploadfor uploading media to the serverGET /api/mediato retrieve a list of uploaded mediaGET /api/media/:idfor streaming media
The focus of this post lies in the third endpoint, responsible for media streaming.
Inspecting the Process
Opening the web server running on http://localhost:3001 , we can find the list of media that we have uploaded through the upload endpoint.
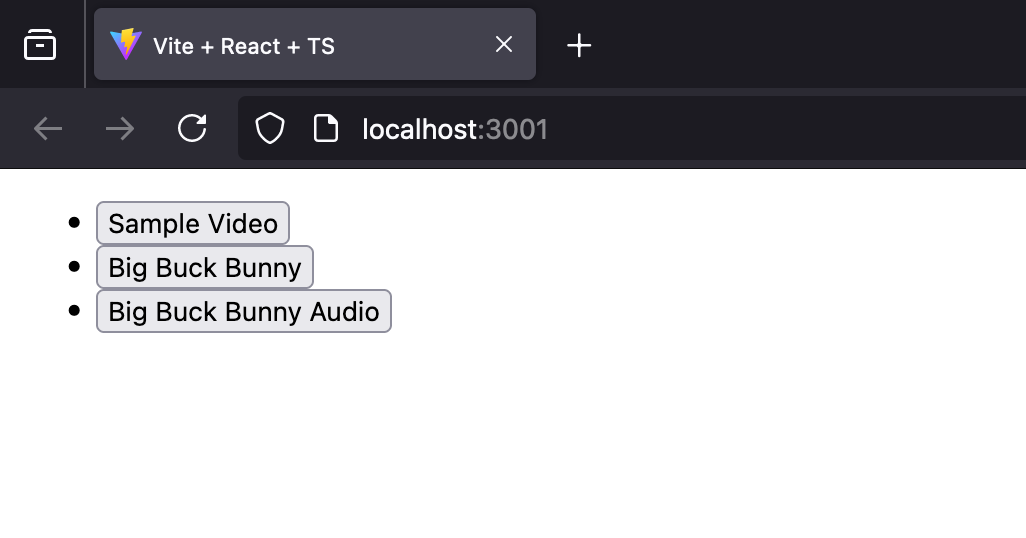
To access a media, just click on the button. Now let's dive deeper by examining developer tools and opening the network tab. Click on a media file you've uploaded (e.g., Big Buck Bunny). You'll observe multiple requests being sent to the server. This might seem counterintuitive, as we only requested a single media file.
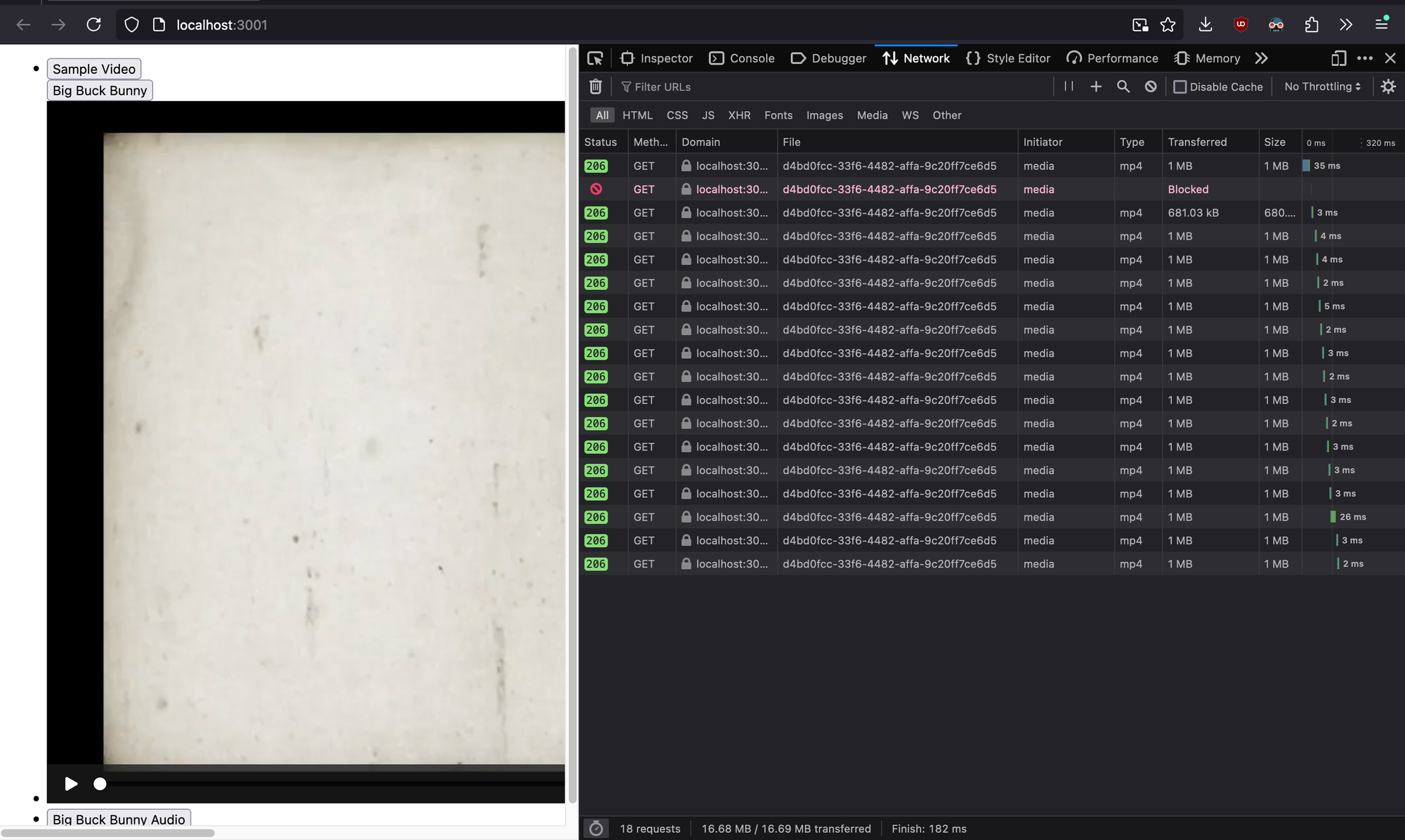
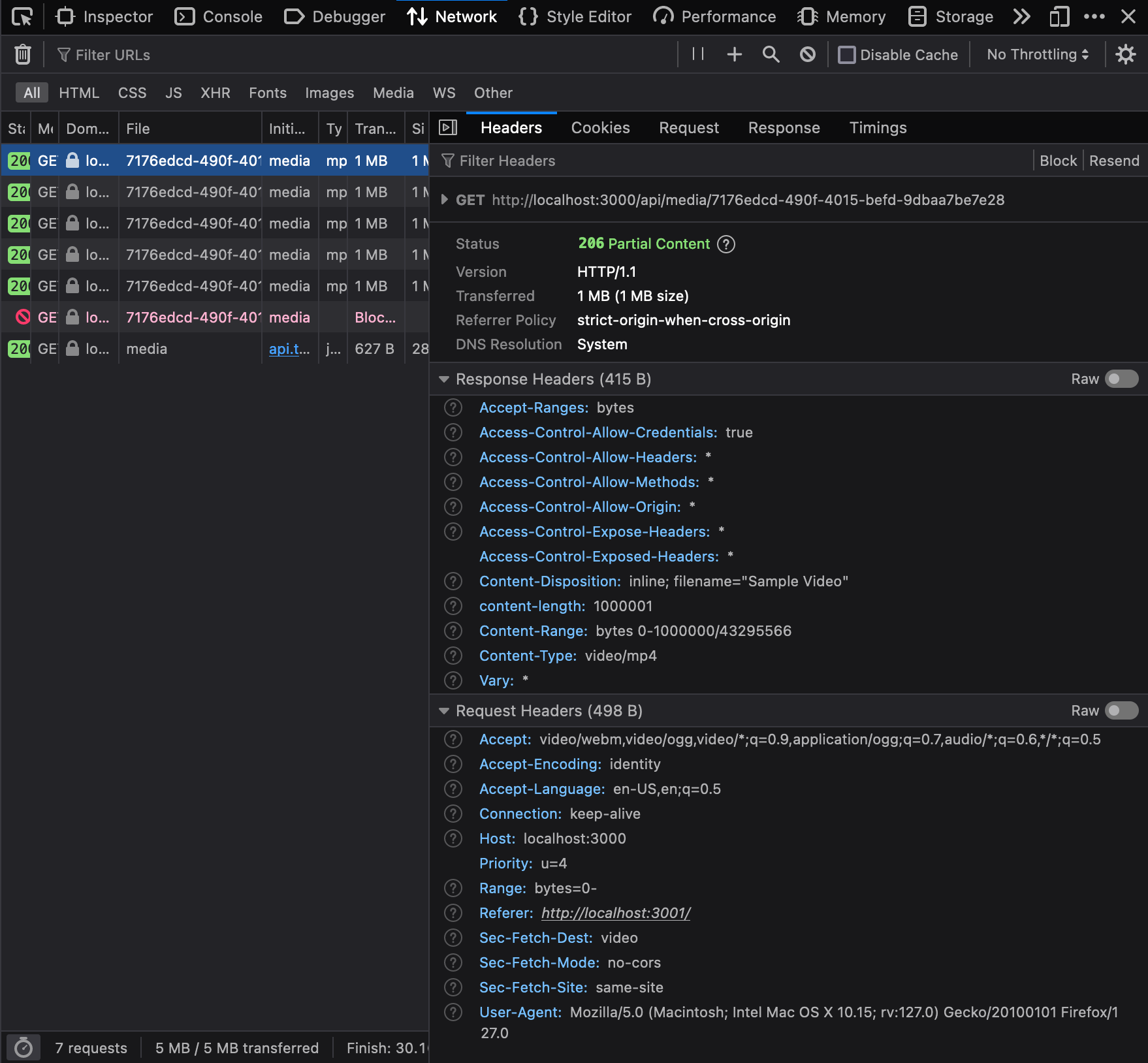
To comprehend this behaviour, let's analyze the initial request sent to the server by the HTML5 video player. Upon closer inspection of the request headers, you'll find a Range header with a value of bytes=0-. This indicates that the HTML5 video player is requesting the server to transmit media content starting from the 0th byte. The server responds by delivering bytes 0 to 1,000,000 out of a total of 43,295,566 bytes.
The apps/api/sec/index.ts file contains the handler responsible for delivering media in chunks:
// additional code here
.get(
"/media/:id",
async ({ params: { id }, set, headers }) => {
const range = headers["range"];
const media = await prisma.media.findUnique({
where: {
id,
},
});
if (!media) throw new NotFoundError();
const file = Bun.file(media.path);
const fileSize = file.size;
const chunksize = 1 * 1e6; // 1MB
const start = Number(range.replace(/\D/g, ""));
const end = Math.min(start + chunksize, fileSize - 1);
const contentLength = end - start + 1;
set.headers["content-disposition"] = `inline; filename="${media.title}"`;
set.headers["content-type"] = file.type;
set.headers["content-length"] = contentLength.toString();
set.headers["content-range"] = `bytes ${start}-${end}/${fileSize}`;
return file.slice(start, end + 1);
},
{
headers: t.Object({
range: t.String(),
}),
params: t.Object({
id: t.String({
format: "uuid",
}),
}),
}
)
// additional code here
Backend code to handle fetching media
In the server code, we parse the Range header transmitted by the client. We've also defined a chunk size of 1MB that the server will utilize for responses. Subsequently, we respond only with the requested byte range from the media file. The server transmits additional headers to communicate details to the client, including file type, the amount of data delivered, and the range of bytes out of the total file size. This bears a resemblance to pagination employed in traditional RESTful APIs.
In traditional streaming, the following code would have sufficed:
// additional code here
.get(
"/media/:id",
async ({ params: { id }, set, headers }) => {
const range = headers["range"];
const media = await prisma.media.findUnique({
where: {
id,
},
});
if (!media) throw new NotFoundError();
return Bun.file(media.path);
},
{
headers: t.Object({
range: t.String(),
}),
params: t.Object({
id: t.String({
format: "uuid",
}),
}),
}
)
// additional code here
Traditional approach to streaming media
The progress bar within the video player reflects the amount of video that has been buffered. As the buffered content nears depletion, the player initiates further requests to the server, fetching more media to buffer. This chunked approach ensures that only necessary data is requested and transmitted, even during media seeking.
In contrast, if the entire file were delivered at once, the progress bar would remain entirely gray until the download is complete. Chunk-based streaming significantly reduces media loading times. Consider a multi-gigabyte movie; with chunk streaming, only the required 1MB chunks are transmitted on demand, rather than the entire file upfront.
It's also worth noting that the BunFile instance doesn't load the entire file into memory, making this approach more memory-efficient. While there may be a slight increase in database calls during media playback compared to traditional methods, the benefits of chunked streaming far outweigh this consideration, especially considering the optimizations that can be implemented.
Conclusion
In conclusion, chunk-based streaming represents a significant advancement in media delivery. By transmitting media in smaller, manageable segments, this approach offers several advantages, including reduced bandwidth consumption, improved loading times, and more efficient memory utilization. As streaming continues to evolve, chunk-based streaming will undoubtedly remain a cornerstone technology for delivering high-quality media experiences to users across the globe.
Thank you for reading this article. See you in the next one.